Past Research Interests of Prof. Keshab K. Parhi
VLSI Digital Filters
Our research in this area has been directed towards design of concurrent algorithms and architectures for VLSI digital filters. In 1960s and 1970s, digital signal processing algorithms were implemented using the available microprocessors which executed the algorithms sequentially. Therefore, there was no motivation for designing concurrent signal processing algorithms, which could exploit pipelining or parallelism. The advances in VLSI technology and parallel processing has changed our thinking style for signal processing algorithm design. Our research efforts in designing concurrent algorithms have been directed towards transforming existing non-concurrent algorithms into concurrent forms as well as designing new algorithms which are inherently concurrent. We have developed look-ahead transformation, decomposition, and incremental computation techniques to create pipelining and parallel processing in signal processing algorithms. In addition, we have proposed sum, delay, and product relaxed look-ahead techniques to design inherently pipelined adaptive digital filters. We have addressed design of pipelined and parallel recursive digital filters, recursive lattice digital filters, recursive wave digital filters, LMS adaptive digital filters, adaptive lattice digital filters, two-dimensional recursive digital filters, and rank-order and stack digital filters. We have also examined finite word-length effects in these filters for fixed-point hardware implementations. Our approaches introduced pipelining in these algorithms. Pipelining of recursive digital filters was considered impossible before. For the first time, we demonstrated feasibility of pipelined stable recursive digital filters. For the first time, we also introduced pipelined architecture topologies for various forms of adaptive filters. For recursive least square (RLS) adaptive filters, we showed that these structures can be easily pipelined by using our proposed Scaled TAngent Rotation (STAR) rather than the common Given's rotation. The STAR rotation is approximately orthogonal as opposed to exactly orthogonal. Recently we have demonstrated that by using Annihilation Reordering Look-Ahead recursive least square (RLS) adaptive filters can also be pipelined based on Givens rotation; these filters maintain exact orthogonality. Truly orthogonal IIR recursive filters have also been developed. These structures provide excellent roundoff noise properties.
Hardware Security: PUFs, TRNGs, and Reverse Engineering
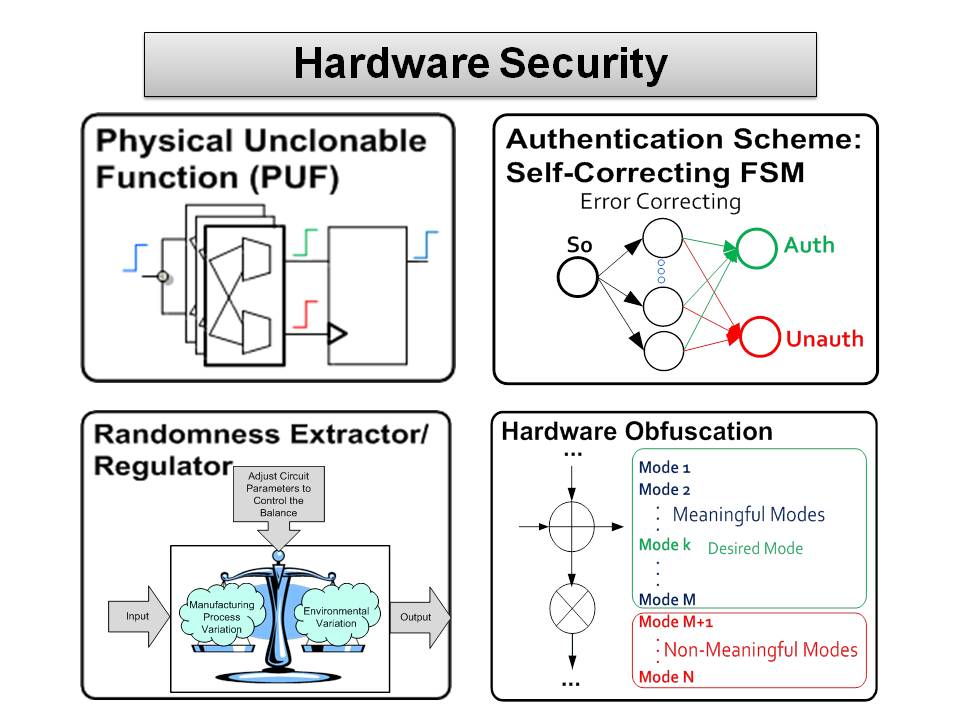
The goal of this research is to use physical unclonable functions (PUFs) for counterfeit prevention of integrated circuit chips and devices, and to simultaneously authenticate devices and users. The objective is to design PUF circuits based on MUX and SRAM PUFs that cannot be hacked easily. Other objectives include designing digital circuits that are harder to reverse engineer.
Other projects in collaboration with Prof. Chris Kim involve design of integrated circuits for true random number generators and physically unclonable functions.
VLSI Speech and Image Coders
Our research efforts in this area are directed towards achieving pipelining and parallel processing in encoders and decoders used for speech and image processing applications. The processing of high-definition and super high-definition television video signals requires very high data rates. It is necessary to design encoder and decoder algorithms which can be pipelined or processed in parallel. When implemented using dedicated VLSI processors or parallel processors, these concurrent algorithms can meet the demands of the high-throughput real-time signal and image processing applications. We have addressed design of high-speed algorithms for predictive coders (including differential pulse code modulation (DPCM), and adaptive DPCM), Huffman and arithmetic decoders, Viterbi decoders (which are variations of dynamic programming computations), arithmetic coders, decision feedback equalizers (DFEs), and adaptive DFEs. The research papers which describe Adaptive DPCM and adaptive DFEs have been listed under "VLSI Digital Filters" category.
We have also developed a number of architectures for VLSI discrete wavelet transforms which require fewer number of registers. The number of registers have been minimized using life time analysis. In addition, we have shown that use of a paraunitary QMF lattice structure in a discrete wavelet transform leads to about fifty percent reduction in hardware area at the expense of an increase in the latency. Various approaches to implementations of DCTs have also been compared. An approach to arbitrarily parallel Variable Length Coder has been developed. This coder architecture accommodates inter-symbol parallelism in an arbitrary manner.
Error Control Coders (Turbo/Block Turbo/LDPC/Viterbi/RS Coders)
Forward-error correction (FEC) codes can be used in almost all kinds of communication systems (wireless, wireline, fiber optic network, etc.) to provide significant gains over the overall transmit power budget of the link, and at the same time, lower the bit error rate. In our group, research work on both soft-decision and hard-decision error control codec has been extensively carried out, which includes the recently discovered powerful Convolutional Turbo Codes, Block Turbo Codes, LDPC Codes (a re-discovery), conventional Convolutional Codes and Reed-Solomon Codes.
Binary and Finite Field Arithmetic Architectures
We have proposed new architectures for two's complement arithmetic operations using an internal redundant number representation. These architectures have been shown to be more area-efficient than the two's complement architectures. This is because our architectures can lead to a large savings in the number of pipelining latches by using our proposed novel redundant-to-two's complement conversion algorithm. We have proposed an adder architecture which was proved to be faster than the previously known fastest Brent-Kung binary-look-ahead adder. A new complex multiply-adder has been developed based on pseudo radix-2 approach.
Residue arithmetic is being exploited for low-power FIR filter implementations. It is shown that the smaller moduli can be operated with lower supply voltage leading to significant power reduction. Efficient modular arithmetic architectures are being developed and these are being used to design efficient RSA cryptosystems.
We have proposed efficient division architectures for radix-2 (with and without prescaling) and radix-4. In addition, we have proposed radix-2 efficient square-root architectures. These algorithms are based on redundant and over-redundant number system representation. In all cases, our algorithms are proven to be faster than known designs. The impact of these architectures can be understood by one example. In radix-2 SRT division (proposed in 1960s), the quotient selection was based on examination of 3 digits of the partial remainder, but we have proposed an algorithm which can perform quotient selection using only 2 digits of the partial remainder. We have developed a shared divider/square-root unit based on Svoboda-Tung approach. It may be noted that no square-root based on Svoboda-Tung approach had been presented before. Low-power divider/square-root chips have also been designed. Low-power CORDIC rotation units are also being investigated.
In addition to radix-2 binary arithmetic, we are also pursuing arithmetic architecture design for finite field (i.e., Galois field) which can be used in error control coding applications. To this end, we have developed some low-area and low-latency finite field multipliers, dividers and exponentiation operators. These operations have been implemented in LSB and MSB first modes and in systolic and semi-systolic forms. Our proposed architectures lead to low latency and low power consumption. Efficient Reed-Solomon coders have been developed based on digit-serial datapaths and appropriate scheduling techniques based on a hardware-software codesign approach.
Design Methodologies for Signal Processing
Our research in design methodologies for signal and image processing is concerned with development of algorithms and design tools for rapid prototyping of these algorithms using either dedicated VLSI chips or commercially available programmable digital signal processors or using field-programmable systems.
We have addressed different implementation styles for dedicated VLSI implementation of signal processing algorithms. In particular, we proposed a systematic unfolding technique to implement digit-serial architectures. Our technique can unfold any bit-serial architecture to a digit-serial architecture in a systematic way. Previous adhoc approaches limited the digit-size to be a divisor of word-length. Our technique accommodates arbitrary digit sizes. Our technique also accommodates multiple rate signal processing algorithms, such as interpolation and decimation. We have also proposed folding techniques to design bit-serial architectures from digit-serial or bit-parallel, and to design digit-serial architectures from bit-parallel ones. The digit-serial circuits designed by unfolding or folding cannot be pipelined at sub-digit levels. To this end, novel digit-serial circuits have been developed which can be pipelined at sub-digit levels.
The folding technique is the reverse of the unfolding technique. The folding technique automatically pipelines and retimes the architecture for folding, and then performs folding. The folding technique has been extended to multirate and multi-dimensional cases also. In this context, an approach to two-dimensional retiming has also been developed.
In hardware system prototyping, we are concerned with high-level hardware synthesis of specified algorithms for specified sample rate constraints, with the objective of minimizing the number of functional units (such as adders, multipliers, latches, buses, and interconnections etc.). We have developed the MARS (Minnesota ARchitecture Synthesis) system for hardware synthesis of signal processing problems. The MARS system makes use of a novel concurrent loop scheduling and resource allocation technique. In addition, MARS reduces the cost of synthesized architecture by accommodating heterogeneous functional types. We have also addressed systematic pipelining, retiming, and unfolding of data-flow graphs for unraveling the hidden concurrency in algorithms. We have also addressed scheduling and resource allocation for fixed multiprocessor architectures for software system prototyping of signal processing problems. In the context of register minimization, we have proposed life time analysis techniques to minimize the number of registers in a data path. We have used this technique to design speech and video data format converter architectures using minimum number of registers. The life time analysis technique can calculate closed form expressions for the minimum number of registers needed for a converter. We have proposed forward-backward register allocation scheme for area-efficient design of converter architectures using minimum number of registers.
We have also proposed optimal synthesis approaches using integer linear programming which peforms synthesis to minimize the total cost of the system in a heterogeneous synthesis environment where some processors could be implemented in bit-serial while others may be implemented in bit-parallel or digit-serial. This model minimizes the cost of data format converters and includes the effect of the latency of these converters on system iteration period. This is the first approach for generalized synthesis of DSP systems using an optimal approach. The MARS system work has also been extended to handle heterogeneous implementation styles.
In the area of fundamental algorithm performance, we have proposed a new algorithm for faster determination of the iteration bound in recursive loops.
In the area of testing, we have examined C-testing of carry-free dividers. Previous C-testing of dividers only considered carry-ripple dividers.
Low-Power DSP System Design
We have developed a two-level hierarchical tool referred to as HEAT tool for estimation of power consumption in datapaths. This tool has been used to estimate power consumption of various adders, multipliers, and complex building blocks such as DCTs. Power estimation for DSP circuits based on switching activity estimation which incorporates glitching and correlation has also been studied.
Various approaches to low-power arithmetic implementations are being addressed. A theoretical approach to power estimation in binary adders based on closed form expressions have been developed. A theoretical approach to estimation of power consumption of multipliers has also been developed. A new type of low-power binary adder referred to as CSMT (carry-select modified tree) adder has been developed; this adder has less power consumption than carry-select and binary tree adders. Various division, square-root and CORDIC architectures are being evaluated for low-power consumption.
Approaches to power reduction in parallel FIR filters through novel strength reduction approaches are being studied.
A novel divided bit-line approach has been developed for low-power implementation of static RAMs.
Novel approaches to power reduction by gate resizing, supply voltage scheduling and threshold voltage scheduling are being studied based on use of retiming approaches.
Various low-power DSP system design approaches by pipelining of DSP structures or novel arithmetic architectures are discussed in VLSI Digital Filters and Binary and Finite Field Arithmetic categories.
Digital Integrated Circuit Chips
Our research also addresses layout design, fabrication and testing of integrated circuit chips for demonstration of key algorithmic ideas. At AT&T, we implemented a VLSI integrated circuit chip for fourth-order recursive digital filtering. This chip is the first recursive filter chip which uses loop pipelining. This chip has been fabricated and tested at 86 MHz sample rate.
At Minnesota, we have already demonstrated implementation of two fine-grain pipelined chips, one for a 16x16-bit multiplier which makes use of internal redundant number representation, and another one for a 100 MHz ADPCM video codec. We have also implemented a shared divider/square-root chip and a bit-level pipelined RLS adaptive filter based on our proposed STAR (Scaled TAngent Rotation) algorithm.
Current research includes implementation of a Viterbi coder chip, another shared divider/square-root and CORDIC chips.
Ultra Wideband Systems
Ultra wideband (UWB) wireless communications have attracted significant attentions from both academic and commercial area. Due to its very high data rates, ultra-low power consumption, robustness to interference and fine ranging capabilities, it has been chosen as candidates for different wireless personal area network (WPAN) standards, including IEEE 802.15.3a and 802.15.4a. Our research work is focused on the low power, area-efficient implementation of different modules in digital baseband system in the wireless UWB systems, including FFT/IFFT processors, time-domain/frequency-domain equalizers, channel code decoders (Viterbi decoders and LDPC decoders). Our research will also address the algorithms related to ranging, geolocation, MIMO-UWB modulation and demodulation.
High-Speed Transceivers
Currently, the IEEE 802.310GBASE-T study group, known as the IEEE-P802.3an Task Force, has completed investigating the feasibility of transmission of 10 Gbps over 4 pairs of unshielded twisted pair (UTP) cables, and is developing its baseline transmission scheme. Like 1000BASE-T, 10GBASE-T achieves 10 Gbps throughput with four wire pairs and eight transceivers (four at each end) with 2.5 Gbps data rate, as shown in the figure below. The target bit error rate (BER) is 10-12.
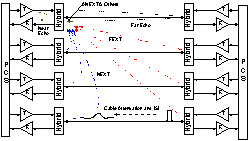
The figure also illustrates the channel conditions. From the figure we can see that the received signal at a receiver not only suffers from signal attenuation and ISI but also suffers from echo, near-end cross talk (NEXT), far-end cross talk (FEXT), and other noises such as alien NEXT (ANEXT). To meet the desired throughput and target BER requirements, we need to perform significant amount of digital signal processing operations in the transceivers, which include channel equalization, channel coding, and echo/NEXT/FEXT cancellation. Our current research interest is focused on high speed, low power and area-efficient implementation of various DSP blocks used in 10GBASE-T Transceiver which include:
- Parallel Decision Feedback Decoders
- High speed Tomlinson-Harashima precoders
- Interleaved trellis coded modulation and decoding
- Efficient long FIR Adaptive Filter Implementation
- Low Power Echo and Next Cancellers
3D Video Systems
Stereoscopic video is two-channel video taken from a binocular camera which provides viewers images with depth information. Recently the auto-stereoscopic display becomes possible due to the development of optical and LCD technology which may make stereoscopic video more popular soon. A simplified object based stereoscopic video coding process is shown in the figure.
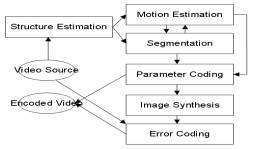
Traditionally, disparity matching is done for each pair of images. However, we proposed two level hybrid disparity matching method suitable for video pair and also ABKB depth map segmentation algorithm. The processing results of these methods can be used for coding purpose. Some 3D motion estimation improving techniques and other techniques are also explored.
Soft-Decision Reed-Solomon Decoder
Recently proposed soft-Decision Reed-Solomon (RS) codes are of great interest in modern communications and storage systems applications. The recently developed Koetter-Vardy (KV) soft-decision decoding algorithm of RS codes can achieve substantial coding gain for high-rate codes, while maintaining a complexity polynomial with respect to the codeword length. In the KV algorithm, the factorization step can consume a major part of the decoding latency. A novel architecture based on root-order prediction is proposed to speed up this step. As a result, the exhaustive-search-based root computation from the second iteration of the factorization step is circumvented with more than 99% probability. In addition, resource sharing among root-prediction blocks, as well as normal basis representation for finite field elements and composite field arithmetic, are exploited to reduce the silicon area significantly. Applying the proposed fast factorization architecture to a typical (255, 239) RS code, a speedup of 141% can be achieved over the fastest prior effort, while the area consumption is reduced to 31%
In the architecture of the fast factorization for the KV algorithm, the root computation and polynomial updating can be carried out simultaneously to reduce the factorization latency further. The latency and area of the polynomial updating account for more than half of the total latency and the total area of the factorization architecture, respectively. Future work will address efficient implementations of polynomial updating. There is no real hardware implementation of the entire KV algorithm so far. The only available implementation is for the interpolation step only, which uses four Xilinx Virtex2000E devices and achieves a maximum clock frequency of 23 MHz. This implementation has overwhelming complexity and runs too slow for practical applications. Current research is directed towards bringing down the complexity of the KV decoding algorithm to practical level through further algorithmic and architectural level optimizations.
LDPC Decoder Architectures
Our research efforts in this area are directed towards designing low-cost LDPC decoder/encoder architectures for high throughput applications. To this end, we have proposed a joint code and decoder methodology leading to a high-speed (3,k)-regular LDPC code partly parallel decoder architecture, based on which we have implemented a 9216-bit, rate-1/2 (3,6)-regular LDPC code decoder on Xilinx FPGA device. The proposed (3,k)-regular LDPC codes have quasi-cyclic (QC) property and high girth so that it can be exploited by partly parallel decoder architecture and also results in a systematic efficient-encoding scheme. We have developed overlapping method of message passing decoding algorithm for a class of QC LDPC codes. By exploring the maximum concurrency of the two stages (check/variable node updates) using a novel scheduling algorithm, the decoding throughput could be increased by about twice. In addition, for a class of QC LDPC codes, a scheme using common hardware to compute both the two processing units has been proposed, which leads to about 21% area reduction of functional units part for a (3, 5)-regular LDPC code. Recently, we are developing LDPC codes and their low-cost decoder architectures for MB-OFDM UWB systems (IEEE 802.15.3a), and high-throughput WLAN (IEEE 802.11n). We have showed that the transmission distance of QC LDPC coded MB-OFDM UWB systems can increase by 29%-73% compared with that of convolutional codes.
VLSI Polar Code Decoders
Polar codes, as the first provable capacity-achieving error-correcting codes, have received much attention in recent years. Our research is concerned with high-speed, low-latency and low-energy architectures for polar code decoders. Both successive-cancellation and belief-propagation decoders are considered.
Computing using Stochastic Logic
The goal of this research is to implement polynomials, functions, digital signal processing and machine learning systems using stochastic logic. Stochastic logic circuits are ideal where area is highly constrained and speed is not a primary concern. Our work has led to more efficient FIR digital filters using scaled stochastic implementations, stochastic implementations of polynomials and arithmetic functions using Horner's rule and factorization, and machine learning classifiers based on radial basis functions and artificial neural networks.
Crypto Accelerators
Cryptography has become a necessity in today's world where data is easily intercepted and copied. Accelerating cryptography has become important for low power devices, routers, and servers. Low power devices would suffer considerable latency without the aid of crypto accelerators. Similarly, routers and servers would not be able to meet the throughput requirements for secure connections without crypto accelerators. Our research has focused on both public key crypto acceleration and symmetric key crypto acceleration. We have developed high throughput crypto accelerator architectures for the Advanced Encryption Standard (AES), the RSA Cryptosystem, and Elliptic Curve Cryptosystems. In 2004, we developed a high speed (21.56 Gbps) FPGA implementation of the AES utilizing a combination of subpipelining and composite field S-Box implementation instead of lookup tables. As for public key cryptography, we have successfully designed an RNS Montgomery multiplier method which does not require CRT base extension but instead utilizes the Montgomery multiplication principle. By folding the systolic array for the Montgomery multiplier twice and using retiming we have designed ring planarized cylindrical arrays which achieve nearest neighbor communication with a linear (not quadratic) increase in total delay elements. Our more recent efforts in elliptic curve cryptography include investigating reconfigurable architectures for GF(p) and GF(2m) and designing cryptographic scalable crypto accelerators.
VLSI Digital Filters and LFSR Circuits
Our current research interests in this area include: 1) Applications of fast algorithms: Parallel FIR filter structures; High speed DCT, DFT and DWT; Parallel FIR adaptive filter structures; 2) High speed circuit design based on VLSI DSP algorithms: Parallel CRC; General Parallel Linear Feedback Shift Register Implementation.
Automated Retinal Imaging from Fundus and OCT Images
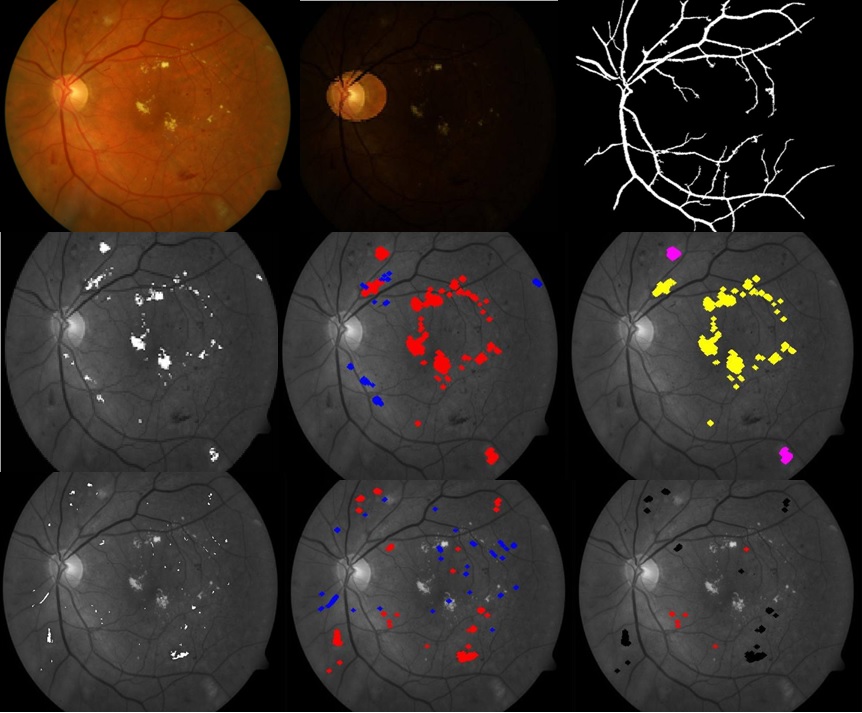
Diabetic retinopathy (DR) is the leading cause of blindness in people of working age in the developed world. The blindness due to diabetes costs US government and general public $500 million annually. A WHO collaborative study projected that the global diabetic burden is expected to increase to 221 million people by 2010. However treatment can prevent visual loss from sight-threatening retinopathy if detected early. In order to address the impact of diabetes, screening schemes are currently being put into place based on digital fundal photography. However, there are concerns regarding the cost of any screening scheme used for detecting sight-threatening diabetic retinopathy in the population. One of the greatest sources of expenditure in setting up any diabetic retinopathy screening program is the cost of financing trained manual graders. If automated detection programs are able to exclude a large number of those patients who have no diabetic retinopathy, it will reduce the workload of the trained graders and thus reduce cost.
Our current research interest is focused on automated diagnosis of diabetic retinopathy using digital fundus images. The images will be graded no DR, mild DR, moderate DR or severe DR based on the type, quantity and the area of lesions present in the eye. Feature extraction is the first step in the classification of these images. The challenge lies in extracting robust features as the image color varies from patient to patient.
In optical coherence tomography (OCT) imaging, the emphasis is on denoising, segmentation, and correlation of layer thicknesses to visual acuity.
This work is in collaboration with Dr. Dara Koozekanani, MD, PhD, of Ophthalmology department at the Medical School.
Lung Sound Signal Processing
Lung diseases seriously threaten human health. Reports from American Lung Association (ALA) show that more than 35 million Americans are living with chronic lung disease such as asthma, emphysema and chronic bronchitis. Every year over 349,000 Americans die from lung diseases. The lung disease death rate has been continuously increasing and become the number three killer in the United States. Lung diseases also cost the American economy $81.6 billion in the direct healthcare expenditure every year, in addition to indirect costs of $76.2 billion - a total of more than $157.8 billion. As statistics have proved that many lives can be saved and much expenditure can be reduced by early detection of lung diseases, a cost-effective, accurate and early detection tool of lung diseases is important and necessary to reduce both the risk of death and the cost of treatment resulted from lung related diseases.
Our current research interest is focused on blind source separation, feature extraction and classification techniques. Blind source separation is a powerful tool to recover the underlying source signals from their observed mixture signals. Feature extraction is used to extract parametric representation, or features, from the input signals. Classification is the last step to classify the features into different groups. Generally speaking, these three subsystems combine to form an intelligent diagnostic system.