Hearing Aid Systems
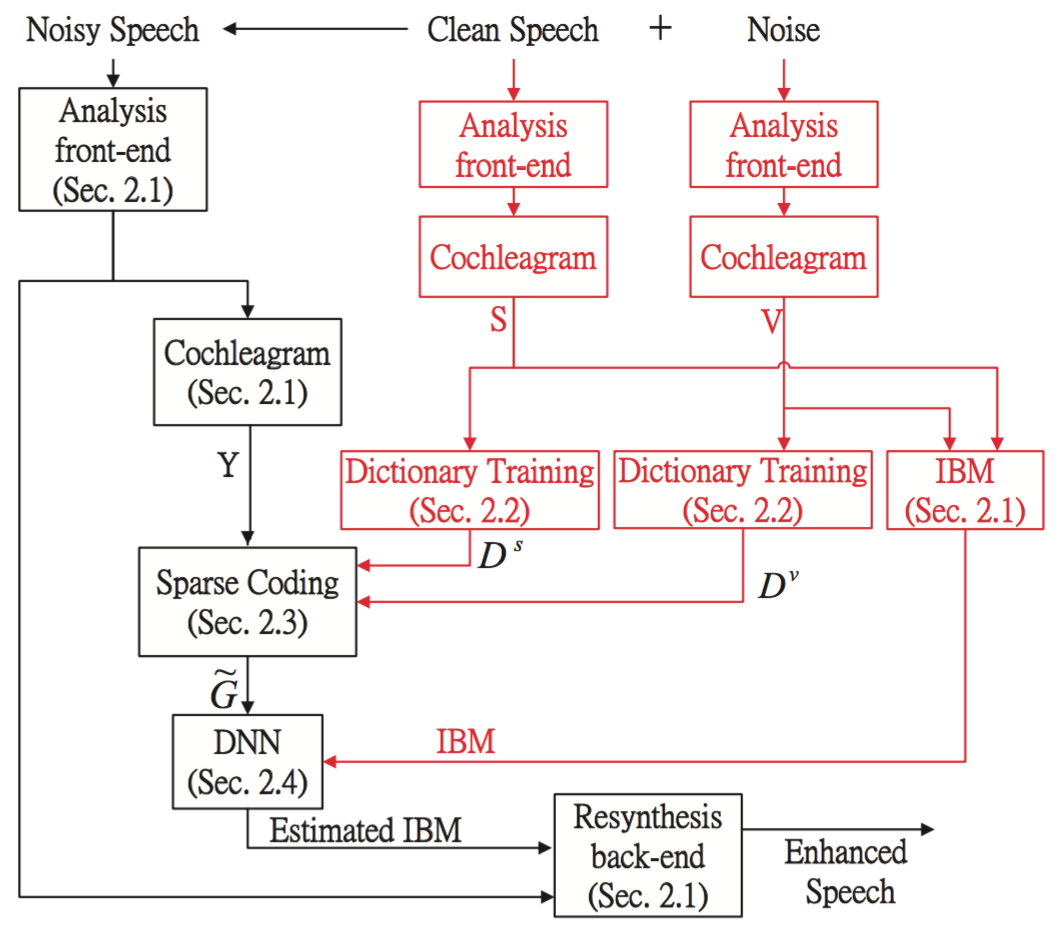 |
SynopsisEnhancing speech from a noisy recording is essential to designing many engineering systems such as hearing aids, mobile communication devices, and robust speech recognition systems. This problem is quite challenging especially when the devices are equipped with a single microphone and we must remove speech-like noises from a single audio stream. Further, effective single-channel enhancement algorithm is of great need since most devices are equipped with a single microphone. We focus on machine learning and optimization based methods, and on leveraging proper prior information of both speech and noise, to perform efficient and high-quality speech enhancement. (image source: [4]) |
Selected Publications
Hung-Wei Tseng, Srikanth Vishnubhotla, Mingyi Hong, Jinjun Xiao, Zhi-Quan Luo and Tao Zhang,“Single channel speech denoising using Wiener plus dictionary learning approach”, Proc. ICASSP 2013
Hung-Wei Tseng, Srikanth Vishnubhotla, Mingyi Hong, Jinjun Xiao, Xiangfeng Wang, Zhi-Quan Luo and Tao Zhang, “A Single Channel Speech Enhancement Approach by Combining Statistical Criterion and Multi-Frame Sparse Dictionary Learning”, InterSpeech 2013
Wei-Cheng Liao, Mingyi Hong, Ivo Merks, Tao Zhang and Zhi-Quan Luo, “Incorporating Spatial Information into Optimal Binaural Noise Supression Design for Hearing Adis”, Proc. ICASSP 2015
Hung-Wei Tseng, Mingyi Hong and Zhi-Quan Luo, “Combining Sparse NMF with Deep Neural Network: A New Classification Based Approach for Speech Enhancement”, Proc. ICASSP 2015; available [https:sites.google.comsitemingyihong84/ICASSP_2015_IBM_DNN_Andy_Final.pdf?attredirects=0&d=1 [here]